
NVIDIA Releases Nemotron-Labs-TwoTower: an Open-Weight Diffusion Language Model Built on a Frozen Autoregressive Nemotron-3-Nano-30B-A3B Backbone
NVIDIA has released Nemotron-Labs-TwoTower, a diffusion language model built on a pretrained autoregressive backbone. It ships as open weights under the NVIDIA Nemotron Open Model License. The release targets a throughput bottleneck in text generation. Autoregressive (AR) models decode one token at a time. That serial process caps generation throughput. Discrete diffusion language models take another route. They generate tokens in parallel and refine them iteratively. Most diffusion langu
Get smart on it
NVIDIA has released an open-weight diffusion language model that generates text faster than traditional autoregressive models by producing multiple tokens in parallel and refining them iteratively rather than generating one token at a time. The model uses a two-tower architecture where a frozen context tower maintains the original language model's knowledge while a trained denoiser tower refines noisy text blocks, achieving 2.42 times higher generation throughput while retaining 98.7% of the baseline model's benchmark quality. This approach addresses a fundamental bottleneck in text generation where autoregressive decoding commits exactly one token per step, whereas the new model can commit multiple tokens per step during the refinement process. The technology offers practical applications including faster batch text generation for synthetic data production and the ability to tune the trade-off between generation speed and output quality from a single checkpoint.
Related news

Google AI Introduces TabFM: A Hybrid-Attention Tabular Foundation Model for Zero-Shot Classification and Regression
Google Research introduced TabFM, a foundation model built for tabular data. TabFM performs classification and regression without dataset-specific training. Every prediction comes from a single forward pass. The model reframes tabular prediction as an in-context learning problem. It is available now on Hugging Face and GitHub. TL;DR TabFM predicts on unseen tables with no training, tuning, or feature engineering. It reads the full dataset as one prompt, then predicts via in-context le
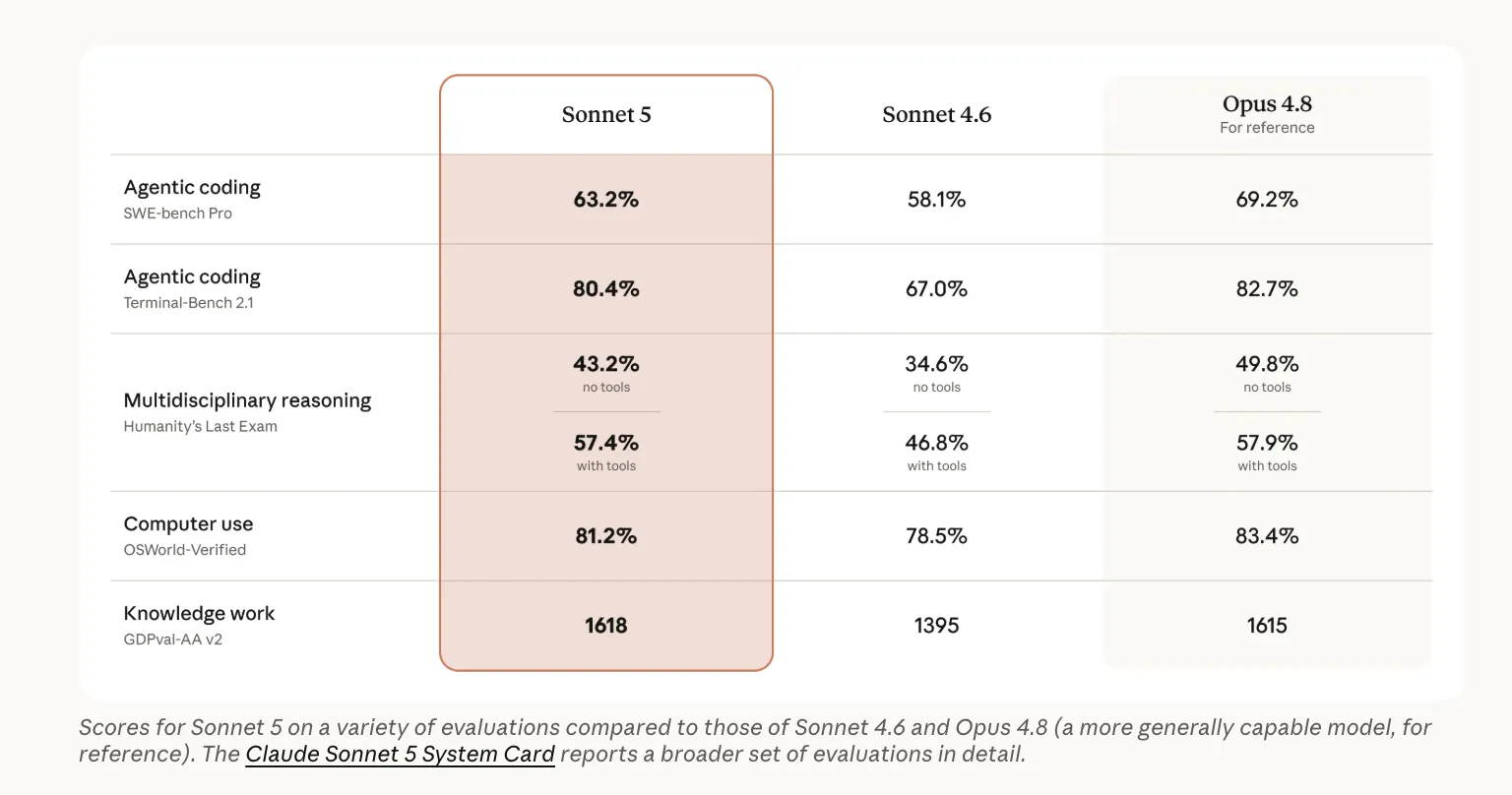
Anthropic Claude Sonnet 5 vs Sonnet 4.6 vs Opus 4.8: Agentic Coding Benchmarks, API Pricing, and Cost-Performance Tradeoffs Compared
Anthropic just shipped Claude Sonnet 5. They call it its most agentic Sonnet model yet. It plans, drives browsers and terminals, and runs autonomously across long tasks. Sonnet 5 is the default model for Free and Pro plans today. Max, Team, and Enterprise users can select it. It is also live in Claude Code and on the Claude Platform. TL;DR Sonnet 5 is Anthropic’s most agentic mid-tier model, closing much of the gap to Opus 4.8. Beats Sonnet 4.6 on every published benchmark: 6



