
DeepReinforce Releases Ornith-1.0: An Open-Source Coding Model Family That Learns Its Own RL Scaffolds
DeepReinforce has released Ornith-1.0, an open-source model family built for agentic coding. The lineup spans four sizes, from a 9B dense model to a 397B mixture-of-experts flagship. Every checkpoint ships under the MIT license on Hugging Face. The models are post-trained on top of pretrained Gemma 4 and Qwen 3.5. Most coding agents pair a model with a fixed, human-designed harness. Ornith-1.0 instead learns to write its own. The DeepReinforce research team reports state-of-the-art results a
Get smart on it
An open-source coding model family called Ornith-1.0 has been released in four sizes, ranging from 9 billion to 397 billion parameters. Unlike typical coding agents that use a fixed human-designed framework, Ornith-1.0 learns to write and refine its own framework during training, optimizing both the framework and the solution together. The models are designed to handle coding tasks like multi-file refactors and bug fixes, and the largest version performs competitively with other open models on coding benchmarks. The release includes safeguards against reward hacking through fixed trust boundaries, action monitoring, and a frozen judge to prevent the model from gaming the reward system.
Related news
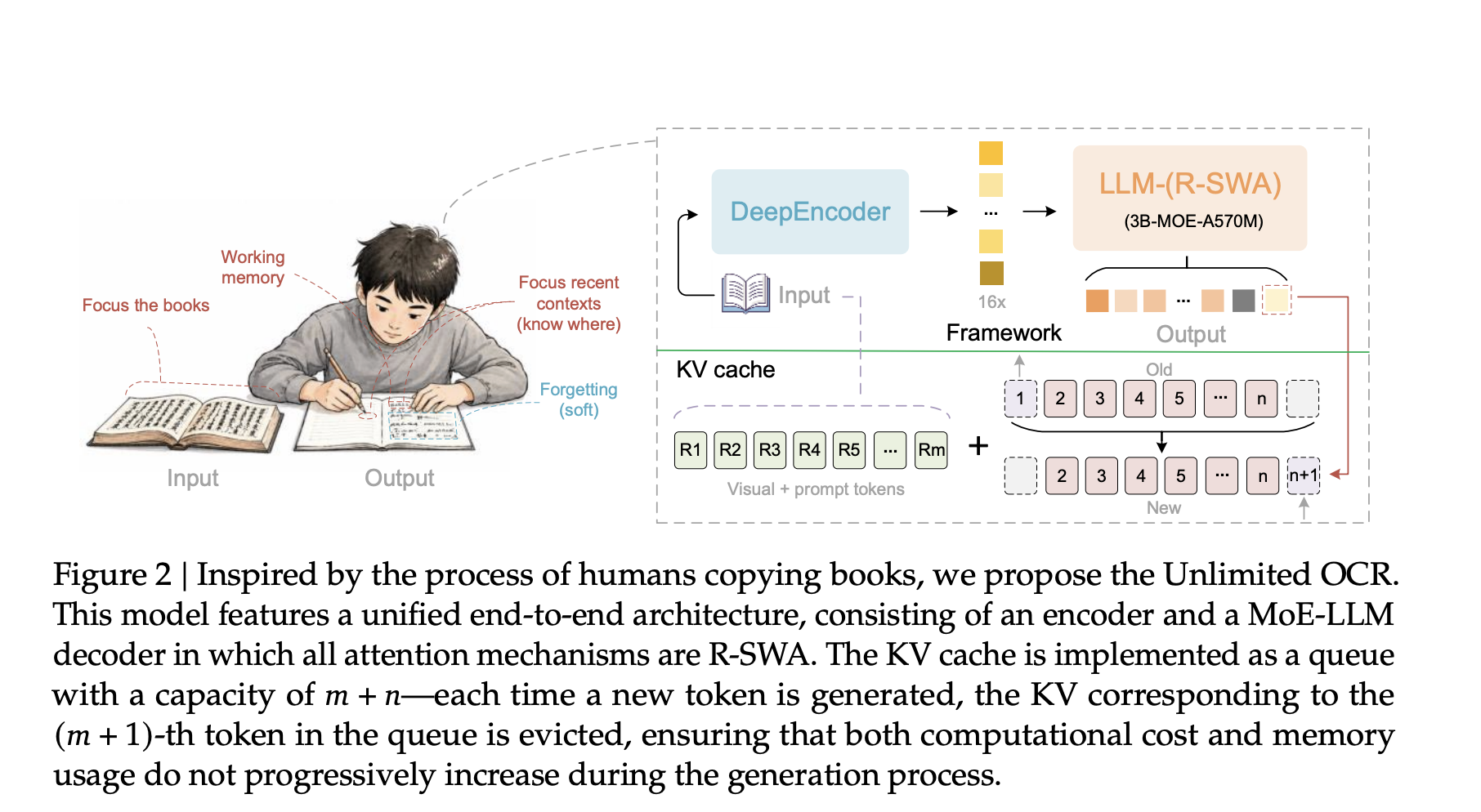
Baidu Releases Unlimited OCR, a 3B Model That Keeps the KV Cache Flat for Long-Document Parsing
Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and generation drags. Parsing dozens of pages becomes impractical. Baidu’s Unlimited OCR addresses this directly. It swaps the decoder’s attention for a design that keeps memory constant. TL;DR Unlimited OCR is a 3B-parameter Mixture-of-Experts model, with only 500M parameters active. It replaces decoder attention with Reference Sliding Window Attention (R-SWA), k

Gradium Launches stt-translate and s2s-translate, Real-Time Speech Translation Models Beating gpt-realtime-translate on Accuracy and Latency
Gradium today released two real-time speech translation models: stt-translate and s2s-translate. Both run across five languages and stream results live in the browser. Gradium claims a better accuracy-latency tradeoff than gpt-realtime-translate and gemini-3.5-live-translate. It also adds output voice control, including cloning, that gpt-realtime-translate lacks. TL;DR Gradium launched two real-time speech translation models: stt-translate (speech → text) and s2s-translate (speech → s



