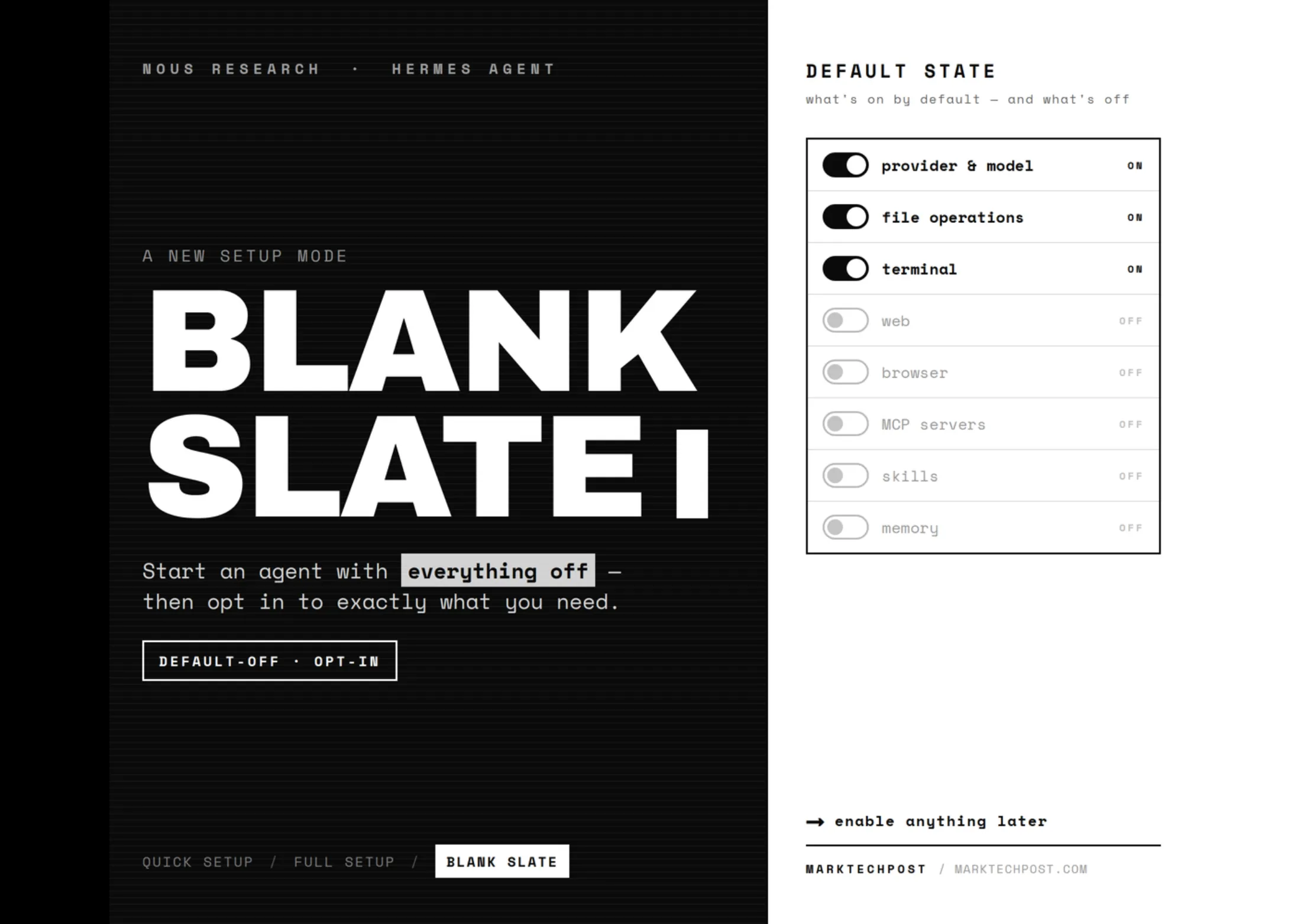
Datalab Releases lift: A 9B Open-Weights Vision Model That Extracts Structured JSON From PDFs Using Schemas
Datalab has released lift, a 9B open-weights vision model for structured extraction. You pass it a JSON schema, and it returns a JSON object that matches. The model reads PDFs and images directly, then decodes against your schema. This is Datalab’s first model built purely for extraction. The team already ships open-source OCR tools: chandra, marker, and surya. lift extends that work into schema-driven field extraction. lift scores 90.2% field accuracy on Datalab’s 225-documen
Get smart on it
lift is a 9 billion-parameter vision model that extracts structured data from PDFs and images by accepting a JSON schema as input and returning matching JSON output. The model uses schema-constrained decoding, which enforces valid JSON structure token by token during generation, ensuring output always matches the correct format. On a 225-document benchmark, lift achieved 90.2% field accuracy while running at a median of 9.5 seconds per document, making it the fastest among comparable self-hostable models. The model is designed with abstention as a default behavior, allowing it to return null for missing fields rather than inventing data, which addresses a key challenge in extraction tasks.
Related news

Mistral OCR 4 Brings Citation-Ready Structured Output to RAG, Agentic, and Enterprise Search Pipelines
Today, Mistral AI released OCR 4, its latest document-understanding model. This new release adds bounding boxes, block classification, and inline confidence scores alongside extracted text. It supports 170 languages across 10 language groups and runs in a single container for fully self-hosted deployments. OCR 4 also serves as an ingestion component for enterprise search, RAG, and domain-specific retrieval pipelines. TL;DR OCR 4 returns bounding boxes, typed-block labels, and per-word c

Introducing Mistral OCR 4
Mistral OCR 4 delivers enterprise document AI with 170-language support, bounding boxes, and self-hosted deployment.