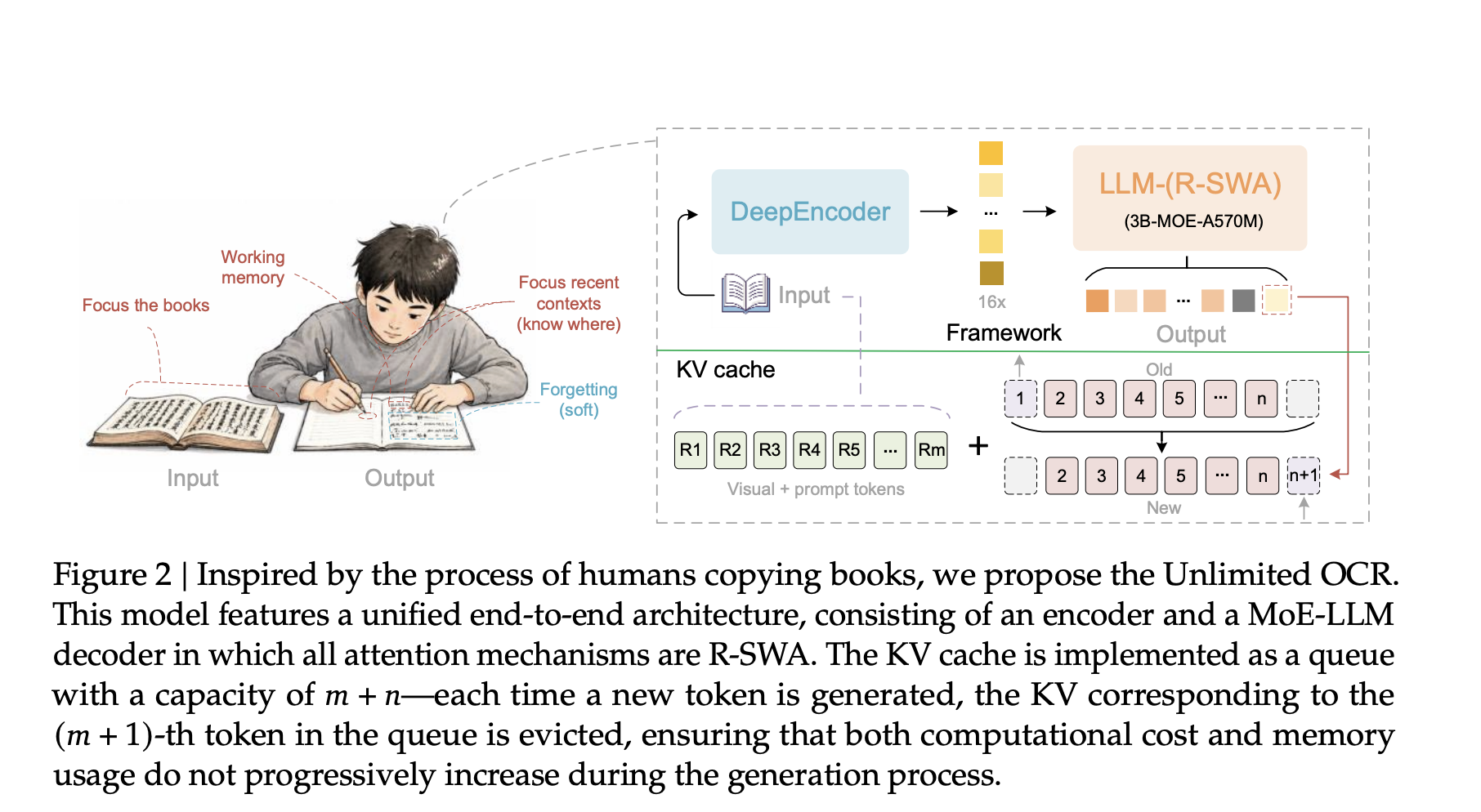
Baidu Releases Unlimited OCR, a 3B Model That Keeps the KV Cache Flat for Long-Document Parsing
Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and generation drags. Parsing dozens of pages becomes impractical. Baidu’s Unlimited OCR addresses this directly. It swaps the decoder’s attention for a design that keeps memory constant. TL;DR Unlimited OCR is a 3B-parameter Mixture-of-Experts model, with only 500M parameters active. It replaces decoder attention with Reference Sliding Window Attention (R-SWA), k
Get smart on it
An open-source OCR model addresses a fundamental problem: as document-parsing models generate more text, their memory requirements grow, slowing down processing. This new model keeps memory constant by using a modified attention mechanism called Reference Sliding Window Attention, which stores only visual tokens and the most recent output tokens rather than all previous outputs. The model achieves this while maintaining high accuracy on document parsing benchmarks and requiring only 500 million active parameters during inference. This design enables practical processing of entire documents, including dozens of pages, in a single pass rather than page-by-page processing.
Related news

Gradium Launches stt-translate and s2s-translate, Real-Time Speech Translation Models Beating gpt-realtime-translate on Accuracy and Latency
Gradium today released two real-time speech translation models: stt-translate and s2s-translate. Both run across five languages and stream results live in the browser. Gradium claims a better accuracy-latency tradeoff than gpt-realtime-translate and gemini-3.5-live-translate. It also adds output voice control, including cloning, that gpt-realtime-translate lacks. TL;DR Gradium launched two real-time speech translation models: stt-translate (speech → text) and s2s-translate (speech → s

Mistral OCR 4 Brings Citation-Ready Structured Output to RAG, Agentic, and Enterprise Search Pipelines
Today, Mistral AI released OCR 4, its latest document-understanding model. This new release adds bounding boxes, block classification, and inline confidence scores alongside extracted text. It supports 170 languages across 10 language groups and runs in a single container for fully self-hosted deployments. OCR 4 also serves as an ingestion component for enterprise search, RAG, and domain-specific retrieval pipelines. TL;DR OCR 4 returns bounding boxes, typed-block labels, and per-word c



