
Why Validation Will Define the Future of HPC and AI
As AI becomes part of HPC workflows, validation, data quality, and trust are emerging as key factors in technology and buying decisions.
Get smart on it
High-performance computing and artificial intelligence are increasingly combined in the same systems, creating a tension between HPC's focus on numerical rigor and reproducibility and AI's statistical, stochastic nature. The key challenge emerging from this combination is validation: determining whether AI outputs can be trusted, especially in high-stakes sectors like healthcare, finance, and energy where accuracy is critical. Unlike traditional HPC competition based on speed and performance, organizations now prioritize validation capability and data quality when making infrastructure decisions. Building validation into the full lifecycle from training through deployment and continuous monitoring, rather than treating it as a one-time activity, is becoming a defining factor for technology providers and a core business differentiator.
Related news

Physics AI research that’s shaping the industry.
Published breakthroughs pushing the state of the art.

GLM-5.2 is the new leading open weights model on the Artificial Analysis Intelligence Index
Benchmarks and Analysis of GLM-5.2
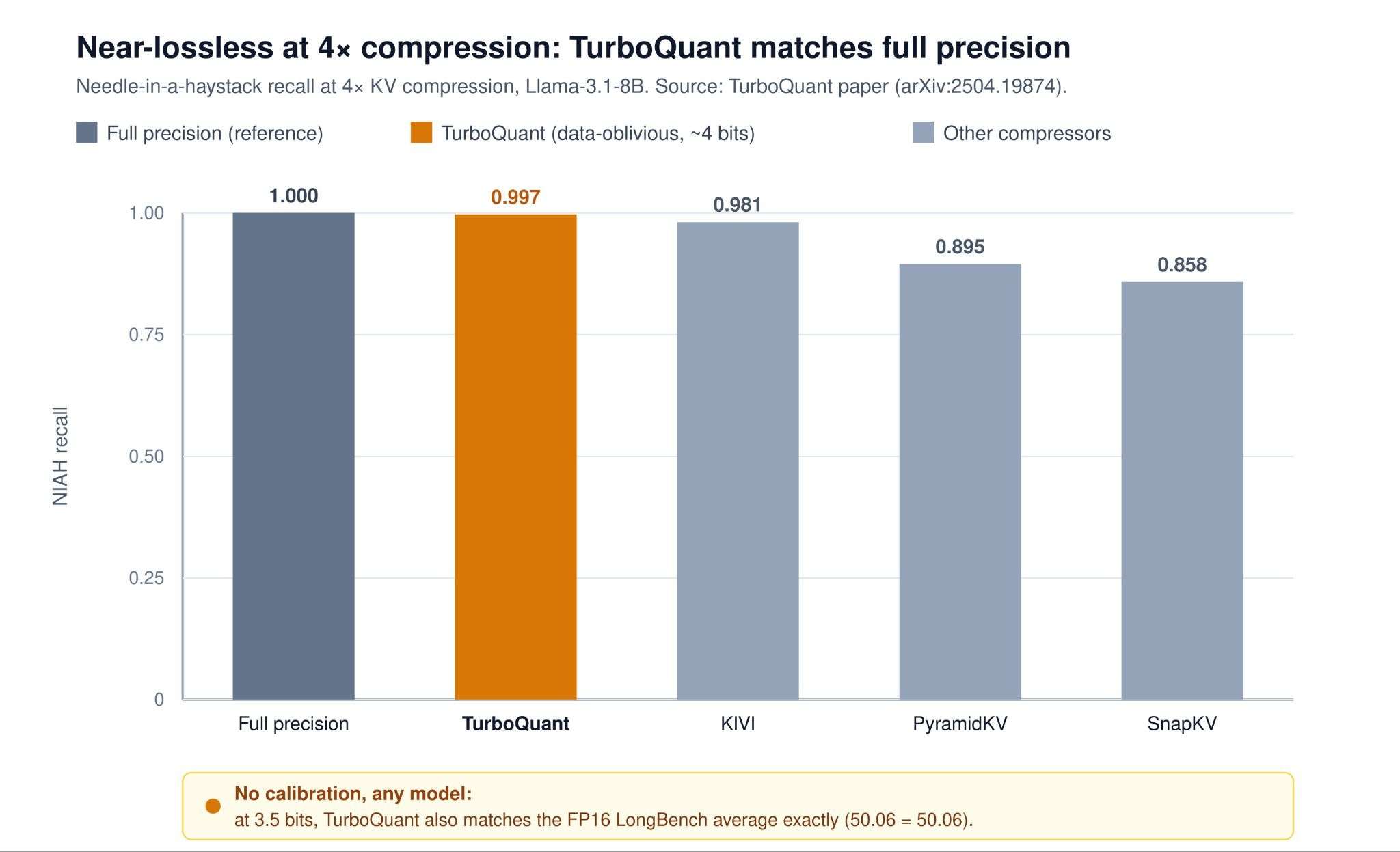
The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache
Long-context large language models (LLMs) face a memory bottleneck that has nothing to do with model weights. During decoding, transformers cache the key and value (KV) vectors for every token at every layer so they don’t have to recompute attention. This cache grows linearly with sequence length and batch size, and at long context with high concurrency it can dwarf the model’s own footprint. Consider Llama-3.1-70B in BF16. Its KV cache costs about 0.31 MB per token (80 layers ×