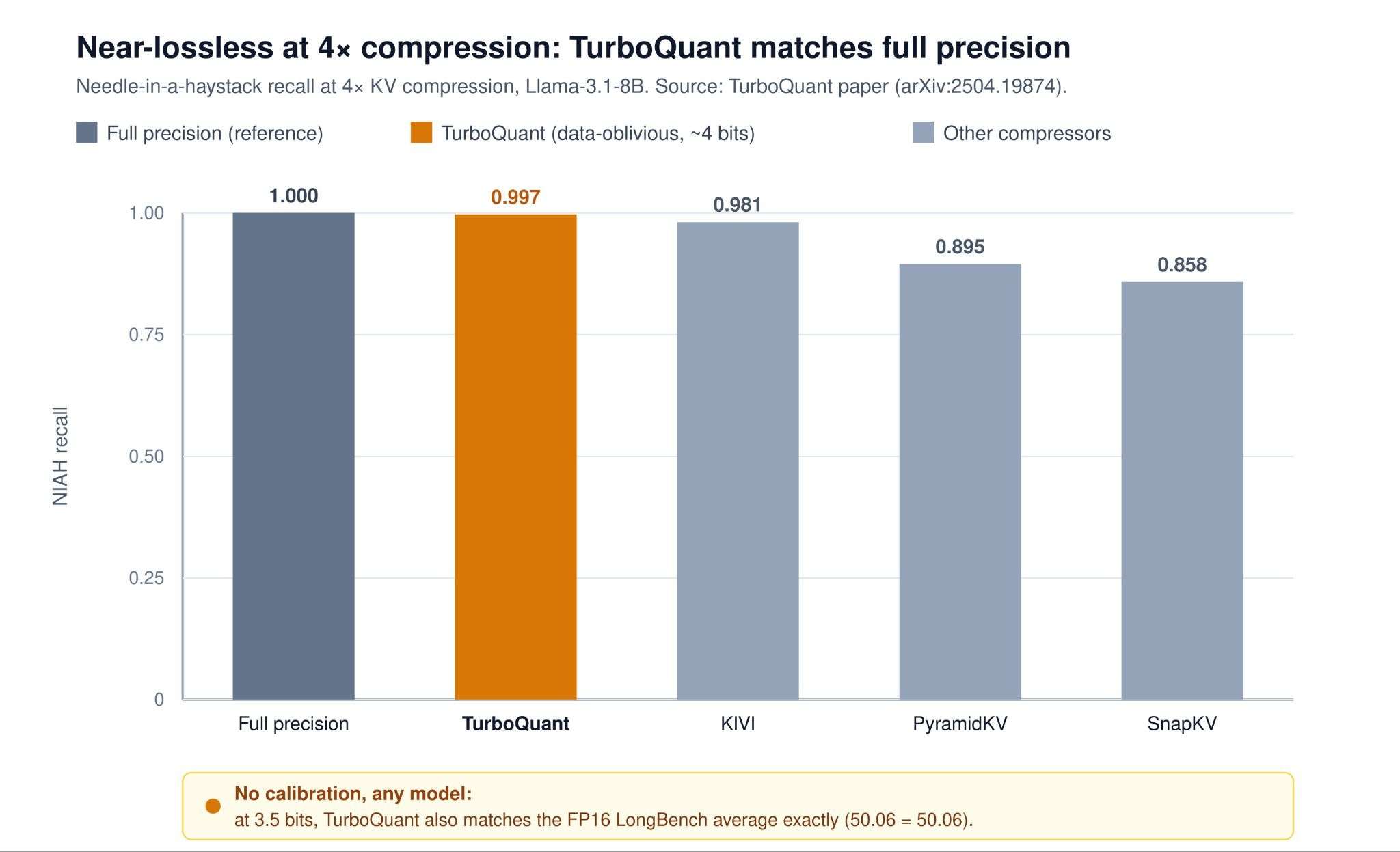
The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache
Long-context large language models (LLMs) face a memory bottleneck that has nothing to do with model weights. During decoding, transformers cache the key and value (KV) vectors for every token at every layer so they don’t have to recompute attention. This cache grows linearly with sequence length and batch size, and at long context with high concurrency it can dwarf the model’s own footprint. Consider Llama-3.1-70B in BF16. Its KV cache costs about 0.31 MB per token (80 layers ×
Get smart on it
Long-context language models face a memory bottleneck where cached key and value vectors grow so large they can exceed the model's own weight footprint, making decoding slow and expensive. Recent compression methods fall into five families: token eviction, quantization, low-rank projection, merging, and architectural sharing, with recent work focusing on ultra-low-bit quantization to shrink these caches. Three competing approaches tackle different aspects of this problem: one uses theoretical optimization without examining data, another uses calibration and attention-aware techniques optimized for deployment, and a third addresses the specific challenge of multi-turn conversations rather than single long contexts. Each method represents different tradeoffs between generality, theoretical guarantees, and practical production readiness.
Related news

Physics AI research that’s shaping the industry.
Published breakthroughs pushing the state of the art.

GLM-5.2 is the new leading open weights model on the Artificial Analysis Intelligence Index
Benchmarks and Analysis of GLM-5.2

Why Validation Will Define the Future of HPC and AI
As AI becomes part of HPC workflows, validation, data quality, and trust are emerging as key factors in technology and buying decisions.