
GLM-5.2 is the new leading open weights model on the Artificial Analysis Intelligence Index
Benchmarks and Analysis of GLM-5.2
Get smart on it
GLM-5.2 is an open weights AI model that has achieved the highest score on the Artificial Analysis Intelligence Index, a benchmark measuring AI performance. The model maintains the same size as its predecessor but scores 11 points higher, with particular improvements in scientific reasoning tasks. It ranks ahead of other leading open weights models and performs comparably to proprietary models on real-world agent tasks, though it uses more output tokens per task and costs more than some competing open weights alternatives.
Related news

Physics AI research that’s shaping the industry.
Published breakthroughs pushing the state of the art.

Why Validation Will Define the Future of HPC and AI
As AI becomes part of HPC workflows, validation, data quality, and trust are emerging as key factors in technology and buying decisions.
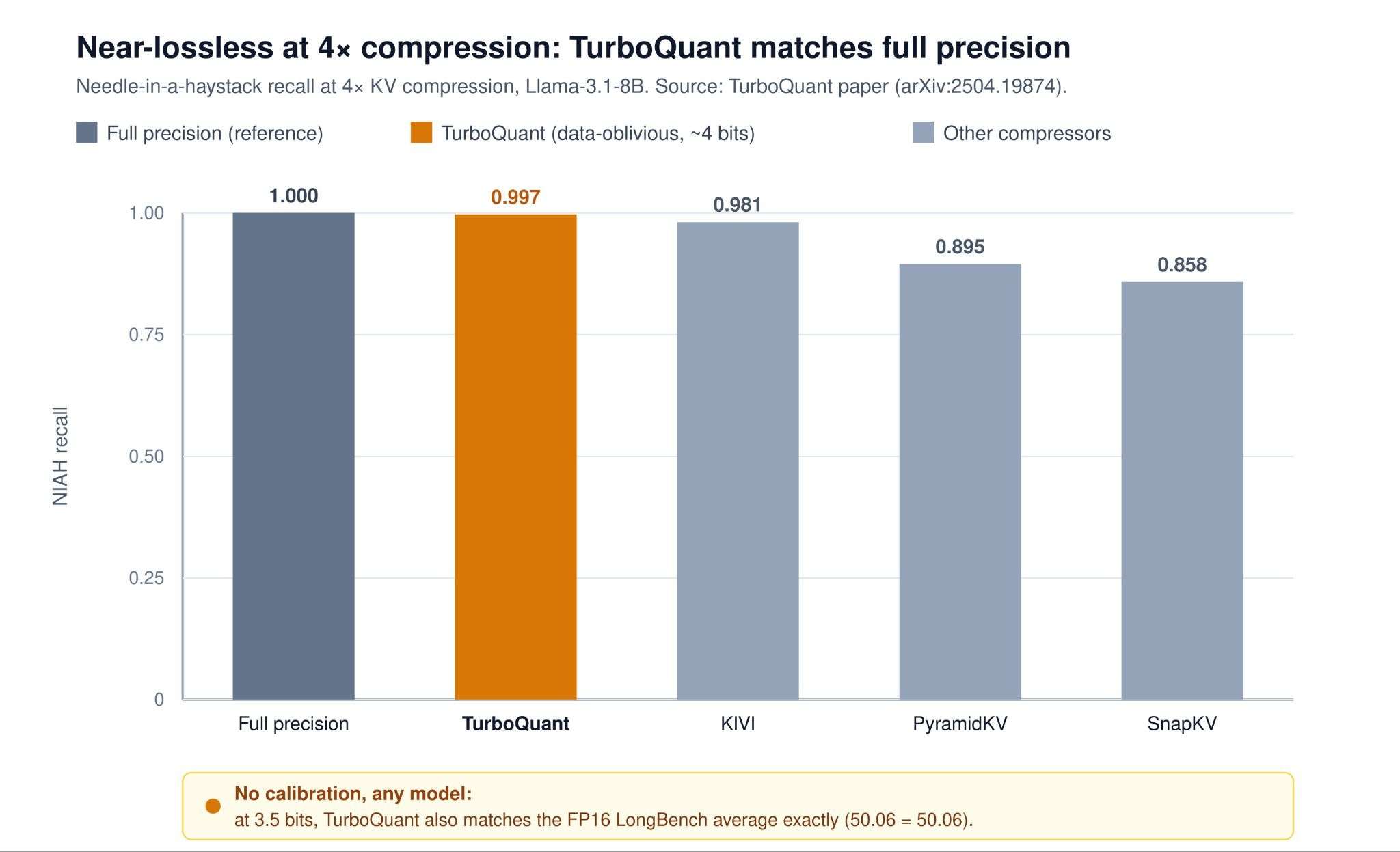
The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache
Long-context large language models (LLMs) face a memory bottleneck that has nothing to do with model weights. During decoding, transformers cache the key and value (KV) vectors for every token at every layer so they don’t have to recompute attention. This cache grows linearly with sequence length and batch size, and at long context with high concurrency it can dwarf the model’s own footprint. Consider Llama-3.1-70B in BF16. Its KV cache costs about 0.31 MB per token (80 layers ×