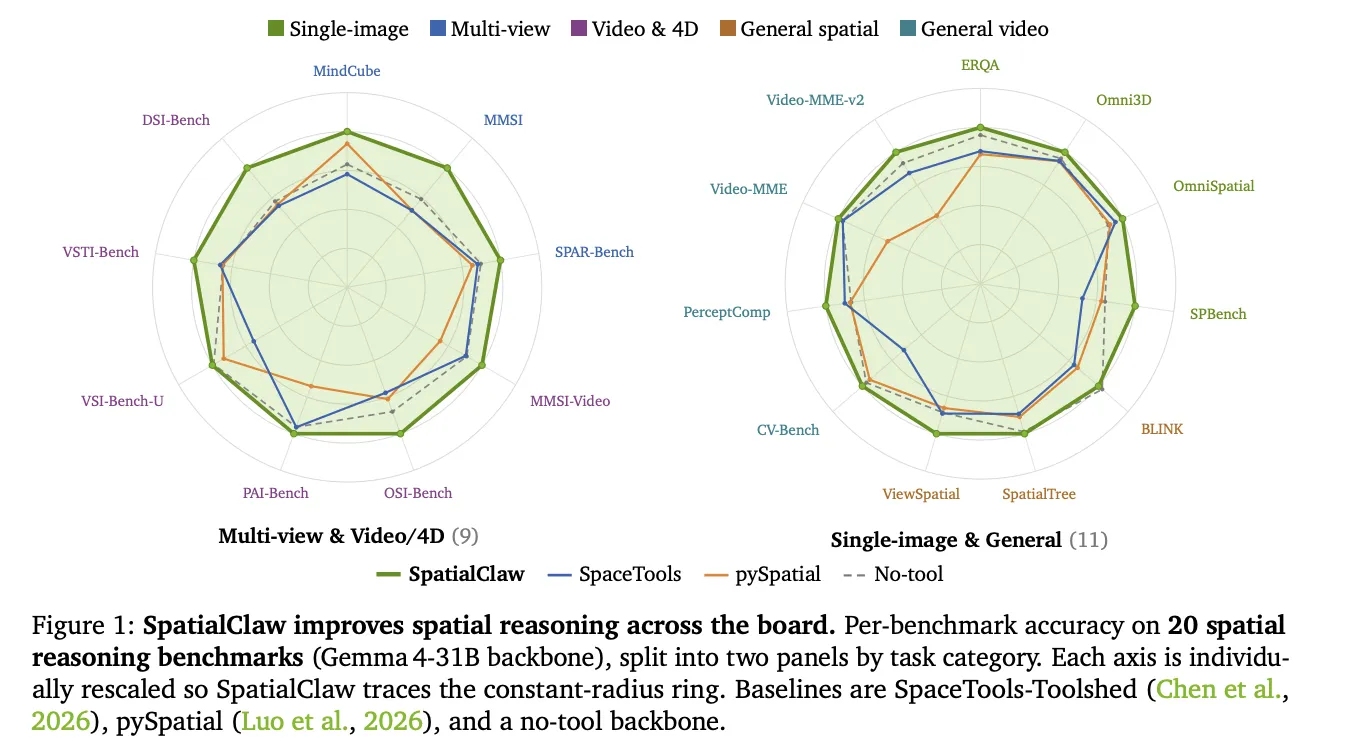
NVIDIA AI Introduce SpatialClaw: A Training-Free Agent That Treats Code as the Action Interface for Spatial Reasoning
NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness in vision-language models (VLMs). These models still struggle to judge where objects are, how they relate, and how they move in 3D. SpatialClaw does not retrain the model. Instead, it changes the action interface the agent uses to call perception tools. The research team argues the interface is the bottleneck. Their solution is to treat code as the action interface. Acr
Make your prediction
Will NVIDIA's SpatialClaw paper appear on arXiv by June 27, 2026?
Resolves by Jun 27, 2026
Your prediction
50% · 50/50 coin flip
NOYES
Get smart on it
SpatialClaw is a framework that helps AI vision systems understand where objects are located in space and how they move, which has been a persistent weakness in these models. Rather than retraining the model, it changes how the AI system takes actions by treating code as the interface, allowing the system to write and execute Python code step by step, inspect results, and revise its approach. Across 20 benchmarks testing spatial reasoning tasks, SpatialClaw achieved 59.9% average accuracy, outperforming the previous spatial agent by 11.2 points, with the largest improvements coming on tasks involving motion tracking and multi-view analysis. The framework is training-free, meaning it can be applied to deployed systems without requiring new data or fine-tuning, and it targets practical uses like robotics, multi-view inspection, and video analysis where geometric reasoning is needed.
Related news

Mistral OCR 4 Brings Citation-Ready Structured Output to RAG, Agentic, and Enterprise Search Pipelines
Today, Mistral AI released OCR 4, its latest document-understanding model. This new release adds bounding boxes, block classification, and inline confidence scores alongside extracted text. It supports 170 languages across 10 language groups and runs in a single container for fully self-hosted deployments. OCR 4 also serves as an ingestion component for enterprise search, RAG, and domain-specific retrieval pipelines. TL;DR OCR 4 returns bounding boxes, typed-block labels, and per-word c

Datalab Releases lift: A 9B Open-Weights Vision Model That Extracts Structured JSON From PDFs Using Schemas
Datalab has released lift, a 9B open-weights vision model for structured extraction. You pass it a JSON schema, and it returns a JSON object that matches. The model reads PDFs and images directly, then decodes against your schema. This is Datalab’s first model built purely for extraction. The team already ships open-source OCR tools: chandra, marker, and surya. lift extends that work into schema-driven field extraction. lift scores 90.2% field accuracy on Datalab’s 225-documen



