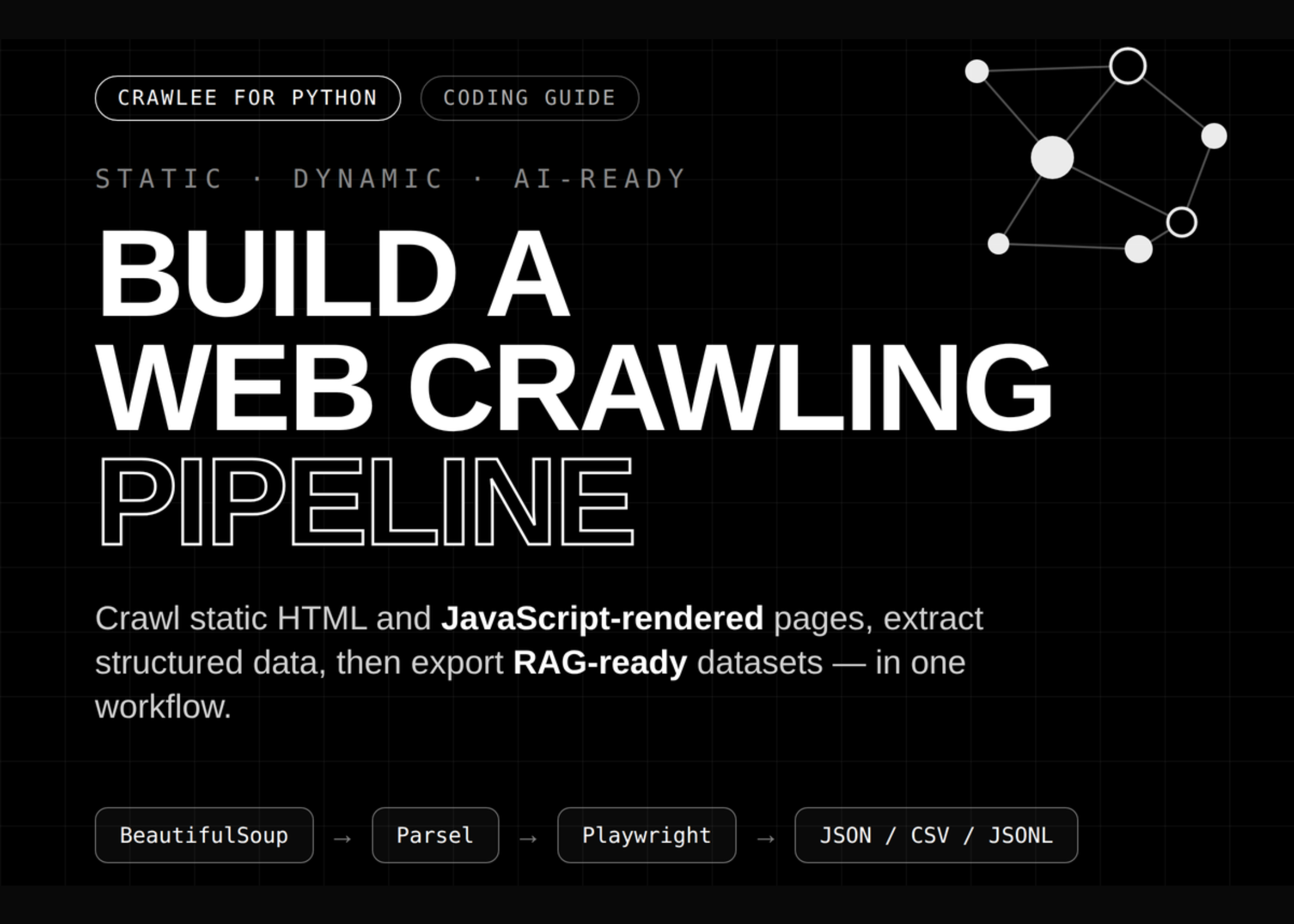
Crawlee for Python: Build a Web Crawling Pipeline with Robots Handling, Link Graphs, and RAG Chunk Export
In this tutorial, we build a full Crawlee-for-Python workflow that covers environment setup, local website generation, static crawling, dynamic crawling, structured extraction, and downstream data processing. We begin by configuring a compatible Crawlee runtime with pinned Pydantic support, Playwright browser installation, persistent storage directories, and Colab-safe execution handling. We then generate a realistic local demo website containing product pages, documentation pages, blog content
Get smart on it
This is a tutorial on building web crawling pipelines using Crawlee for Python, covering three types of crawlers: BeautifulSoupCrawler for fast HTML extraction, ParselCrawler for precise CSS and XPath-based extraction, and PlaywrightCrawler for rendering JavaScript content in a headless browser. The tutorial demonstrates practical workflows including environment setup, generation of a demo website with product pages and documentation, extraction of structured data like titles and metadata, and handling of dynamic DOM elements. These techniques matter because they enable automated data collection from websites at different complexity levels, from static HTML to JavaScript-rendered content, with features for respecting robots.txt rules and exporting data for downstream processing like retrieval-augmented generation (RAG) applications.
Related news

India’s MoEngage bets that the future of marketing is millions of AI agents
The all-cash deal gives MoEngage access to technology that assigns AI agents to individual customers.

Google Home will soon get better at recognizing you
A new update for Google Home could make it less likely your smart home cameras mistake you for someone else, just because you're facing away from the camera. Starting June 23rd, Google's expanding its facial recognition feature so that people you've tagged in your Familiar Faces library can continue to be identified when their faces aren't clearly visible, using "additional non-biometric signals (body size, clothing color, etc.)." The Familiar Faces library will also begin aut